C/C++のビルド過程のメモ(The C++ Build Process Explained)
序文
C++のビルド過程が忘れつつありましたのでそれに関する良い文書を探し、復習を兼ねてメモしてみました。
参照リンク
本文
1. Overview
C++のビルド過程は既存のC言語のビルド過程に基づき築かれている。C++のビルド過程中にリンギングはコンパイラーより違うかもしれないし、CとC++のスタンダードでは正確なリンギングを記していない。しかしほぼ全てのC++コンパイラは挙動がほぼ同じである。(説明文ではリンギングを説明するためにGNUを使う)

- C/C++のSourceファイルがたくさんある。
- 各ソースファイルに独自の単位でコンパイラを通す
- 現在のファイルにフリープロセッサーを通す。マクロが置換する。
- 従属するヘッダーや親ファイルの内容を入れ込める。
- 最終的にソースファイル
.c.cppがコンパイルされ、オブジェクト.oに変換する。
.oオブジェクトファイルを纏めて実行可能なファイルまたはライブラリーへ変換する。
2.1 Trivial C Program
ここからはCプロフラムのソースコードを参照にして説明する(そうだ)。そしてコンパイラはccをつかう。
ccというプログラムはOSプラットフォームによって違われるが、Linuxではg++かgccを指す。
add.h
#ifndef ADD_H_INCLUDED #define ADD_H_INCLUDED int add(int a, int b); int sub(int a, int b); #endif // ADD_H_INCLUDED
add.c
#include "add.h" int add(int a, int b) { return a + b; } int sub(int a, int b) { return a - b; }
simple.c
#include <stdio.h> #include "add.h" int main(int argv, char **argc) { printf("%i\n", sub(add(5, 6), 6)); return 0; }
2.2 Why Headers?
mainにてadd関数を呼ぶとすると、そのadd関数から返すリターンタイプとそのadd関数がどのタイプの引数を受け止めるかを確かめないといけない。なのでadd関数を呼ぶとしたら以下のような手順を踏む。
A. main関数にて
- リターン値に対するメモリ空間をスタックに生成する。(
add関数はstdcallだと見なす。) - スタックに
aとbに対する引数のための空間をスタックに生成する。 - そして
add関数が終わったあとでmain関数から中断したところに戻るため、リターンアドレスをスタックに入れる。 add関数があるアドレスへ移動する。(jmpとかcallとか)
B. add関数にて
- レジスタなどの関数が実行される前のプロセッサーの状態をどこかにセーブする。
aとbを足してレジスタかまたはメモリ空間に値を入れる。今のadd関数では値を即リターン値として扱うため、リターン値の対するメモリ空間に値を入れる。add関数が実行される前のCPUの状態に戻す。- リターンアドレスを読んで、
main関数に戻る。
C. main関数に戻ってから
- スタックから引数の
aとb値をポップする。(無くす) スタックにあるリターン値を別のところに使う。
CまたはC++言語で関数の呼び方やスタックの作り方は各コンパイラによって違うかもしれない。この呼び方や作り方をABIとする。(Application Binary Interface)もし同じコンパイラだとしてもOSや使っているCPUによって異なるABIを使うかもしれない。複雑になるが、効率になる。
上記に「リターン値やパラメータのためのメモリ空間を作る」とあるが、そうするにはそのパラメータとリターン値のタイプに関するサイズが必然必要となる。そのため、ヘッダーファイルをインクルードする。
- もしパラメータかリターンタイプがポインターか参照だったら、そのタイプに関するサイズを求めなくても良い。これを利用してコンパイル速度をあげようとしたのが
PIMPLというイディオムである。
2.3 Preprocessor
- 各文の最初に
#があるのは、その文章はCフリープロセッサーを通すことを示す。
フリープロセッサー以下の作業を行う。
#includeインクルード- Cマクロ拡張 (
#define RAGTODEG(x) ((x) * 57.29878)) - Cフリープロセッサー分岐作成 (
#if#ifdef#endifなど) ファイルの状態に従属するラインコントロール (
__FILE____LINE__)注意すべきところは
#include <>と#include ""に対し、C/C++スタンダードは細かい挙動を提供していない。<>か""によっての挙動は全てコンパイラが賄う。
3. Header Trees
- ヘッダーファイルをインクルードするとき、インクルードするヘッダーファイルが他のヘッダーファイルをインクルードするとしたら、急にビルド時間が遅くなりメモリか性能を相当消費することになりやすい。
今筆者のソースコードをコンパイルするとき、
-Hオプションを入れて幾つかのファイルが実際のコンパイルに関与するかを調べた結果、作成したファイルは3個なのに22個もコンパイルされることがわかる。
4. Object File
3.からの手順か終わってからコンパイラが各ソースファイルをコンパイルしてオブジェクトファイル.oにすることが出来る。- オブジェクトファイルは他のオブジェクトファイルとのリンギングがまだしてないままのアセンブリコードを持つ。
simple.o
simple.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 48 89 75 f0 mov %rsi,-0x10(%rbp)
f: be 06 00 00 00 mov $0x6,%esi
14: bf 05 00 00 00 mov $0x5,%edi
19: e8 00 00 00 00 callq 1e <main+0x1e>
1a: R_X86_64_PLT32 add-0x4
1e: be 06 00 00 00 mov $0x6,%esi
23: 89 c7 mov %eax,%edi
25: e8 00 00 00 00 callq 2a <main+0x2a>
26: R_X86_64_PLT32 sub-0x4
2a: 89 c6 mov %eax,%esi
2c: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 33 <main+0x33>
2f: R_X86_64_PC32 .rodata-0x4
33: b8 00 00 00 00 mov $0x0,%eax
38: e8 00 00 00 00 callq 3d <main+0x3d>
39: R_X86_64_PLT32 printf-0x4
3d: b8 00 00 00 00 mov $0x0,%eax
42: c9 leaveq
43: c3 retq
ここで注目するところは、2つがある。
- アセンブリコードが
<main>関数でグループ化している。 - そして
0x19番地のcallq 1e <main+0x1e>が今リンギングされていない他のオブジェクトファイルの関数の<add>関数を指している。(0x25 = <sub>も同様)
5. Symbol Tables
- 各オブジェクトファイルの最上部ではこのオブジェクトで定義された関数のリストと、そして他のオブジェクトファイルで参照する(こっちでは定義されてない)関数のリストのリストがある。これを
Symbol Tableという。
次のようにシンボルテーブルを取り出すことが出来る。
nm add.o > add.sym nm simple.o > simple.sym
add.o
| Position | Type | Name |
|---|---|---|
| 0 | Text | add |
| 14 | Text | sub |
simple.o
| Position | Type | Name |
|---|---|---|
| Undefined | add | |
| Undefined | GLOBAL_OFFSET_TABLE | |
| 0 | Text | main |
| Undefined | printf | |
| Undefined | sub |
6. Linkerがやること
実行できるファイルにするには生成したオブジェクトファイルを一緒に組んでリンギングをしなければならない。しかしここにそれを実現する2つの方法にまた分かれる。
シンボルテーブルによる関数の遷移先を直接リンクしてテーブルなしに直に関数へ飛ぶようにする。(スタティック)
- 関数への遷移先を記したテーブルを用意し、関数の呼び出しのときにテーブルをルックアップして遷移するようにする。(ダイナミック)
スタティックにする方法は効率的だが、ライブラリには向いてない。反面、動的リンクは静的リンクよりはやや遅いが、柔軟でライブラリの配布に向いている。
7. C++でビルドする時との違い ~ 8. A Basis for Objects
- 昔のC++のコンパイラはあくまでもC++のコードをCのコードに変換する、即ち前処理コンパイラだったそうだ。
- しかし今のC++では
TemplateとLambdaとそしてManglingというものがあって、Cコンパイラとは細部的としては違う。
この文書で筆者はTemplateは説明せずにManglingだけを説明している。例として以下のコードがあるとする。
extern "C" int add_c(int a, int b) { return a + b; } int add(int a, int b) { return a + b; } int add(const int *a, const int &b) { return *a + b; } float add(float a, float b) { return a + b; } namespace manu { int add(int a, int b) { return a + b; } }
そしてコンパイルをして出るオブジェクトファイルのシンボルテーブルを調査すれば以下のように結果が出る。
| Position | Type | Name | Signature |
|---|---|---|---|
| 0 | Text | add_c | int add_c(int, int) |
| 14 | Text | _Z3addii | int add(int, int) |
| 28 | Text | Z3addPKiRS | int add(const int*, const int&) |
| 44 | Text | _Z3addff | float add(float, float) |
| 5e | Text | _ZN4manu3addEii | int manu::add(int, int) |
- C言語ではシンボルテーブルの関数の名前がプログラマが指定してネームとして扱われるが、C++ではNamespaceかLambdaかTemplateかそしてClassのメンバー関数かによって同じ関数名であってもスコープが違ったりする。なのでC++ではManglingを使ってコンパイラから指定されたネームを実質的な関数名としてする。
extern "C"はC++のManglingを消すようにする。こうして既存のCと交換性を持つ。- Manglingの規則はまたコンパイラごとに違う。しかし今はほぼ全てのコンパイラがItanium C++ ABIで指定して基準化された規則を使う。
Mangling(Itanium C++)の規則は下のリンクを参照する。 github.com
MSVCは独自のフォーマットを使うらしい。ひでぇ
- C++のオーバーローディングを実装するために静的ディスパッチを実行する。そしてオーバーローディングした関数はコンパイルを通してからは全部異なる関数名を持つ。
はてなブログでLaTeXを使いたかったのでまとめメモ
序文
git pageを運用していた時には、を使用するために
MathJaxを導入して使っていました。ですけどはてなブログに移転してからを導入して使用する方法がないかわかりませんでした。
ですけどちょっと探してたらははてなブログにビルトインとして設置されており、そして
MathJaxを導入しているということが分かりました。ですのでこの記事を持ってメモを纏めてみたいと思います。
本文
1. 使い方
[tex:{ \LaTeX }]
上のように、markdownエディタで[tex:{と}]を使って、その中に構文を入れます。
例として以下の構文があるとします。
[tex:{ \displaystyle
b_n = \sum_{m=0}^{N-1} a_m
}]
上記の構文は以下のように見えます。
2.  の記号
の記号
下のリンクを参考にしてください。(多すぎてまとめられないです。)
結論
ばりばり使いましょう
参照リンク
Segment Treeを使用して部分和を計算する。
Segment Tree とは
Segment Treeはバイナリツリー(二分木)を使用して区間やあるリストの範囲を貯蔵するに使われるデータ構造である。Segment Treeは実装するリストの長さに対していつも平衡二分探索木である。なので探索に最悪O(lgN)がかかる。Segment Treeを使用すれば、クエリーを用いてある特定の区間の部分和をO(lgN + K)で求めることができる。Kとは求められる区間の部分区間の個数を指す。
| Segment Tree | 数式 |
|---|---|
| 要素の数 | |
| ツリーの深さ | |
| ツリーのメモリ | |
| ツリーの空間複雑度 | |
| 生成の時間複雑度 | |
| 部分和の時間複雑度 | |
になる。
Segment Treeはリストが長く、そしてリストの要素の数が固定されて頻繁にリストの要素が値が切り替わるときに有用になる。
コード
Segment Tree 実装

- Segment Treeの実装に注意する点は、インプットとして入れたリストの要素の位置はツリーの葉部分であることだ。
- そして葉が生成される位置は、ツリーの左から寄せて生成するのではなく再帰に沿って仮想の完全二分木の葉の部分かそれとも葉の親部分を葉として扱ってそれらからの一つに葉が生成される。なので
Segment Treeを生成する時には、空白の葉ノードが必要となる。
using TSegmentTree = std::vector<int>; using TValueList = std::vector<int>; TSegmentTree::value_type MakeSegmentTree( const TValueList& valueList, TSegmentTree& segmentTree, const unsigned nodeIndex, const unsigned valueStart, const unsigned valueEnd) { if (valueStart == valueEnd) { segmentTree[nodeIndex] = valueList[valueStart]; } else { const auto sep = (valueStart + valueEnd) / 2; segmentTree[nodeIndex] = MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 1, valueStart, sep) + MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 2, sep + 1, valueEnd); } return segmentTree[nodeIndex]; }
部分和の関数実装
- 部分和を実装する関数を作る時には、区間の範囲だけでなくツリーの範囲まで入れないとならない。何故なら再帰によって既に計算された部分区間の和が入った親ノードを選ぶかないかを決定しなければならない為だ。
- もし再帰で今求められる区間が部分ツリーが持っている葉の要素のインデックスの範囲の相応していたら、今指している親ノードの部分和の値を返す。
- それとも区間が外されている場合にはまた掘り下げて葉まで下る。
- 区間が範囲の完全に外していたらその部分ツリーでは値を求む必要がないので
を返す。
[[nodiscard]]
TSegmentTree::value_type GetPartialSum(
const TSegmentTree& segmentTree,
const unsigned targetStart, const unsigned targetEnd,
const unsigned treeStart, const unsigned treeEnd,
const unsigned id = 0) {
// Special case
if (targetEnd < treeStart || treeEnd < targetStart) { return 0; }
if (targetStart <= treeStart && treeEnd <= targetEnd) { return segmentTree[id]; }
// General case
const auto sep = (treeStart + treeEnd) / 2;
return GetPartialSum(segmentTree, targetStart, targetEnd, treeStart, sep, 2 * id + 1)
+ GetPartialSum(segmentTree, targetStart, targetEnd, sep + 1, treeEnd, 2 * id + 2);
}
値切り替えの関数実装
- 値を切り替える場合にも再帰を積極的に使う。
- ただし、切り替えを
で終わらせてまた
Constant Factorを減らすためには今切り替えをする値に対し、既存の値との差を求めてその値が入る予定の葉までの親ノードに入っている部分和の値を新たに演算しなければいけない。
void UpdateValue( TSegmentTree& segmentTree, const unsigned valueId, const int difference, const unsigned treeStart, const unsigned treeEnd, const unsigned treeId = 0) { // Special case if (valueId < treeStart || valueId > treeEnd) { return; } // General case segmentTree[treeId] += difference; if (treeStart == treeEnd) { return; } const auto sep = (treeStart + treeEnd) / 2; UpdateValue(segmentTree, valueId, difference, treeStart, sep, 2 * treeId + 1); UpdateValue(segmentTree, valueId, difference, sep + 1, treeEnd, 2 * treeId + 2); }
結果
// 最初のインプットリスト 5 6 8 3 1 3 1 4 2 4 // Segment Treeの各ノードの値 37 23 14 19 4 8 6 11 8 3 1 4 4 2 4 5 6 0 0 0 0 0 0 3 1 0 0 0 0 0 0 // 部分和の結果リスト Start : 0 ~ End : 0 = Sum : 5 Start : 0 ~ End : 1 = Sum : 11 ... Start : 0 ~ End : 7 = Sum : 31 Start : 0 ~ End : 8 = Sum : 33 Start : 0 ~ End : 9 = Sum : 37 Start : 1 ~ End : 9 = Sum : 32 Start : 2 ~ End : 9 = Sum : 26 ... Start : 8 ~ End : 9 = Sum : 6 Start : 9 ~ End : 9 = Sum : 4 // 新たな値リスト 17 -34 -59 71 86 25 83 33 53 -89 // 更新したSegment Treeの各ノードの値 186 81 105 -76 157 141 -36 -17 -59 71 86 108 33 53 -89 17 -34 0 0 0 0 0 0 25 83 0 0 0 0 0 0
コード全文
#include <cstdio> #include <vector> #include <algorithm> #include <utility> #include "../../Common/CheckTime.hpp" using TSegmentTree = std::vector<int>; using TValueList = std::vector<int>; TSegmentTree::value_type MakeSegmentTree( const TValueList& valueList, TSegmentTree& segmentTree, const unsigned nodeIndex, const unsigned valueStart, const unsigned valueEnd) { if (valueStart == valueEnd) { segmentTree[nodeIndex] = valueList[valueStart]; return segmentTree[nodeIndex]; } else { const auto sep = (valueStart + valueEnd) / 2; segmentTree[nodeIndex] = MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 1, valueStart, sep) + MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 2, sep + 1, valueEnd); return segmentTree[nodeIndex]; } } [[nodiscard]] TSegmentTree::value_type GetPartialSum( const TSegmentTree& segmentTree, const unsigned targetStart, const unsigned targetEnd, const unsigned treeStart, const unsigned treeEnd, const unsigned id = 0) { // Special case if (targetEnd < treeStart || treeEnd < targetStart) { return 0; } if (targetStart <= treeStart && treeEnd <= targetEnd) { return segmentTree[id]; } // General case const auto sep = (treeStart + treeEnd) / 2; return GetPartialSum(segmentTree, targetStart, targetEnd, treeStart, sep, 2 * id + 1) + GetPartialSum(segmentTree, targetStart, targetEnd, sep + 1, treeEnd, 2 * id + 2); } void UpdateValue( TSegmentTree& segmentTree, const unsigned valueId, const int difference, const unsigned treeStart, const unsigned treeEnd, const unsigned treeId = 0) { // Special case if (valueId < treeStart || valueId > treeEnd) { return; } // General case segmentTree[treeId] += difference; if (treeStart == treeEnd) { return; } const auto sep = (treeStart + treeEnd) / 2; UpdateValue(segmentTree, valueId, difference, treeStart, sep, 2 * treeId + 1); UpdateValue(segmentTree, valueId, difference, sep + 1, treeEnd, 2 * treeId + 2); } int main() { // Make valueList; std::vector<int> valueList = {}; for (int i = 0; i < 10; ++i) { valueList.emplace_back(neu::test::GetRandomValue<int>(1, 10)); } // Print valueList; for (const auto& value : valueList) { std::printf("%d ", value); } std::puts(""); // Make segment Tree; const auto height = static_cast<unsigned>(std::ceil(std::log2(valueList.size()))) + 1; std::vector<int> segmentTree((1 << height) - 1, 0); MakeSegmentTree(valueList, segmentTree, 0, 0, valueList.size() - 1); // Pritn segment Tree. for (const auto& value : segmentTree) { std::printf("%d ", value); } std::puts(""); // Get Sum from segmentTree rapidly O(lgN) unsigned start = 0; unsigned end = 0; while (end <= valueList.size() - 1) { std::printf("Start : %u ~ End : %u = Sum : %d\n", start, end, GetPartialSum(segmentTree, start, end, 0, valueList.size() - 1) ); ++end; } end--; while (start <= end) { std::printf("Start : %u ~ End : %u = Sum : %d\n", start, end, GetPartialSum(segmentTree, start, end, 0, valueList.size() - 1) ); ++start; } // Update value and get overall sum. std::vector<int> diff(valueList.size()); for (auto i = 0u; i < valueList.size(); ++i) { const auto newValue = (neu::test::GetRandomValue<int>(-100, 100)); diff[i] = newValue - valueList[i]; valueList[i] = newValue; } // Print valueList; for (const auto& value : valueList) { std::printf("%d ", value); } std::puts(""); for (auto i = 0u; i < valueList.size(); ++i) { UpdateValue(segmentTree, i, diff[i], 0, valueList.size() - 1); } // Print segment Tree. for (const auto& value : segmentTree) { std::printf("%d ", value); } std::puts(""); };
参照リンク
Segment tree - Wikipedia 세그먼트 트리(Segment Tree) 요약 정리 (C++) – Jang
Gallery of Processor Cache Effectsを読んでメモ
参照リンク
Gallery of Processor Cache Effects
Example 1 : Memory accesses and performance
int[] arr = new int[64 * 1024 * 1024]; // Loop 1 for (int i = 0; i < arr.Length; ++i) { arr[i] *= 3; } // Loop 2 for (int i = 0; i < arr.Length; i += 16) { arr[i] *= 3; }
- 理論上、Loop1がLoop2より凡そ16倍くらい遅れるそうけど、実際にはそうでもないことがわかる。記事ではほぼ同じ処理時間を持って
80msと78msが測定するそうだ。 - なぜなら、配列を構成するメモリーが一列で整列されているとしたら、Loop1とLoop2を処理するにメモリの特定地点に接近するために同じ時間を費やさなければならない。ここでキャッシュが関与してしまう。
Example 2 : Impact of cache lines
for (int i = 0; i < arr.Length; i += K) { arr[i] *= 3; }
でKの増加による処理時間を測定したらこうなる。
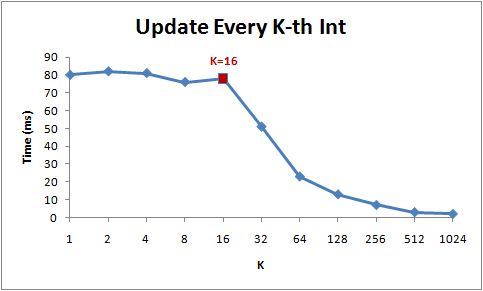
- 1から16までは理論としては処理時間が減少の傾向を見せるべきだが、実際にはそうでもないことがわかる。そして16からは急に処理時間が減少していることが分かる。
- 何故なら、現在のCPUはメモリの領域に接近する時にバイト単位で接近せずに64Bytes単位として扱う。この各64BytesをCache Lineという。メモリの特定領域を読むときに、そのCache Lineが取り出されてCacheにフェッチされる。よって、同じCache Lineでの接近は処理速度を速くする。(メモリーの地域性)
- よって16個を超えてステップをするようにすると、キャッシュミスになり、また別のCache LineをCacheに乗せなければならない。とあるデータ構造でのノードがCache Lineを犯して頻繁に接近を求めていたら犯しているCache Lineの分に処理時間が遅くなる可能性がある。
Example 3 : L1 and L2 Cache sizes
現代のCPUではキャッシュのレベルがあり、L1,L2そしてL3レベルのキャッシュメモリーが提供されている。筆者はL1メモリーの容量は32KBで、そしてL2メモリーの容量は4MBだらしい。
筆者はCache LineやCache Missを研究するために大きい配列にCache Lineごとを接近するようとしたコードを作成した。そして配列のサイズによる各要素の処理速度を測定する。
int steps = K * (1024 * 1024); for (int i = 0; i < steps; ++i) { // Start time arr[(i * 16) & arr.Length]++; // End time }
結果として得られた処理時間のグラフは以下のようになっている。
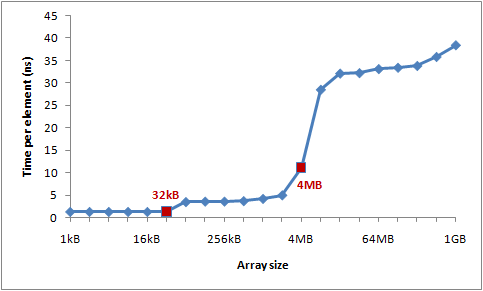
- L1キャッシュミス、そしてL2キャッシュミスによる処理時間の増加のようだ。
Example 4 : Instruction-level parallelism
int steps = 256 * 1024 * 1024; int[] a = new int[2]; // Loop 1 for (int i=0; i<steps; i++) { a[0]++; a[0]++; } // Loop 2 for (int i=0; i<steps; i++) { a[0]++; a[1]++; }
上記のLoopでは最適化によってLoop1がLoop2より遅くなる可能性がある。g++かclangのようなC++コンパイラとはまた違うが、C#のCLR JITコンパイラーは{ a[0]++; a[0]++; }を{ a[0] += 2; }で返さない。すなわち、このような従属性が生じてしまう。

- Loop2の場合には、命令語レベルの並列性が発生するため同時にL1キャッシュの変数
a[0]とa[1]に接近することができる。 - Loop1の場合、CLR JITによる最適化が行っていない場合並列処理が発生しないため速度が落ちる可能性がある。
- だとしても、コンパイラによって最適化が出来るかないかが分かれるので状況によって違われるかもしれない。
Example 5 : Cache associativity
メモリーの領域をどうやってキャッシュに乗せるかについてはいくつかの方法がある。メモリー空間をマッピングするには3つの方式がある。
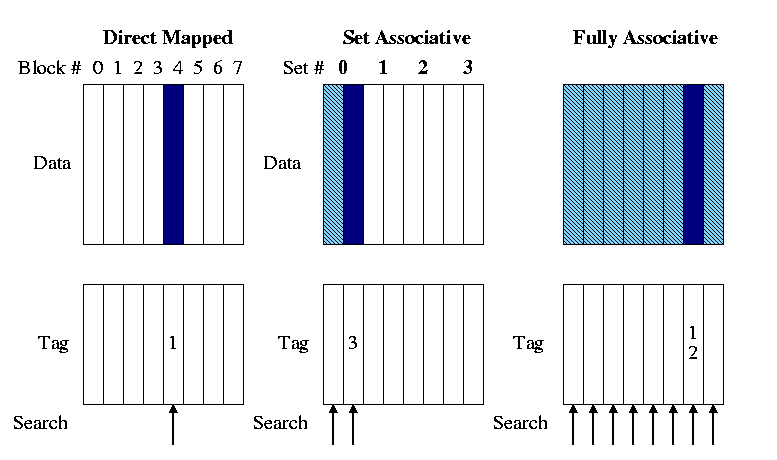

- Directed Mapped Cache
MLBからのいくつかのビットを使用し、そのままCacheにインデックスやあとでキャッシュを参照する時に使われるTagに適用する上位ビットをマッピングするものを指す。もし4GBの物理的メモリがあるとしてキャッシュは64Bytes分の番地が乗せるようになっていたら、その64Bytes分のCacheに載せられる数は64MB個になる。そのため、キャッシュミスが起こりやすい。
N-wayから見ればDirected Mapped Cacheは1-Way set associative Cacheかもしれない。indextagvalid bitoffset

- N-way set associative Cache
メモリの領域がK個で別れていて、そしてキャッシュにメモリブロックごとに一個ずつでのべ最適K個の
Setが指定され、そしてSetには指定されたメモリブロックのIndexやTagを持つようにしたN個のライン(Line)があるもの。Directed Mappedとの違いは、キャッシュを検証する時にN個を同時に検証することと構造がより優れるためキャッシュヒット率がDirected Mapped Cacheより高いのが長所である。 そしてもっと発展した構造であるFully Associative Cacheが実装しやすいという点もある。

- Fully associative Cache
Indexがなく、全てのCache lineを一つのN-way setと見なす。そのためキャッシュを検証する時にはすべてのキャッシュラインを同時に検証する。しかしIndexがなくTagOffsetだけで構成するため、検証が難しい。もしキャッシュミスが起こった場合にはN-wayのようにLRUFIFORoundrobinなどのアルゴリズムを使って代替を行う。
筆者のL2キャッシュは4MBでそして16-way set associative cacheで駆動しているそうだ。そして64Bytesもメモリブロックが一個のセットとしてあるとして32ビットの環境なら一個のセットにつき16スロットが配分される。
またキャッシュにはスロットの数の制限もあり、今の場合には65536個が限界となっている。だとしたら今使えるセットの個数は4096個となる。セット付きに一つのインデックスが割当するので2^12 = 4096個として12ビットがインデックスとして活用される。そうなればメモリの領域で一つのセットに干渉するメモリ空間の隔ては4096 * 64 = 262,144Bytesになる。こうして普通のDirected Mapped Cacheより効率を上げられる。
public static long UpdateEveryKthByte(byte[] arr, int K) { const int rep = 1024*1024; // Number of iterations int p = 0; for (int i = 0; i < rep; i++) { arr[p]++; p += K; if (p >= arr.Length) p = 0; } }
上記のコードをテストとして使用して、キャッシュによる処理速度を検証する。Kは配列の各番地を渡るステップとして扱われる。

上の画像はステップと配列のサイズによって違われる処理時間をグラフとして表示したものである。青ければ青いほど処理時間が遅い。
- ステップが
64になるまでは大差が出ない。キャッシュのほぼ全てのセットを周期的に接近するし、そして集中的に特定のセットのキャッシュ検証が行われていないからかもしれない。 128256512から見える青い先はキャッシュメモリの同じセットに集中的に接近し、アドレスを検証したり接近するため処理時間が遅くなることを示す。- 配列の大きさが
4MB以下では速度が速くなることは、今筆者のL2キャッシュメモリが4MBの容量と16-wayで配列の全ての変数の値に対するアドレスを全部入れることが出来るからだ。今各セットにつき262,144Bytesを間隔としているなら262,144 * 16 = 4MBになる。
Example 6 : False cache line sharing
- 普通L1キャッシュは各プロセッサーについており、L2からのキャッシュメモリは複数のプロセッサが共有する。
- マルチコアプロセッサの環境では接近する変数のメモリに対するキャッシュラインが同じであれば、むしろ速度が落ちることがある。何故なら、各プロセッサーが変数に接近して値を更新するたびに他のプロセッサーが持っているキャッシュラインを無効化してしまう。こういうことは普通各プロセッサーが共有するL2メモリで起こりやすく、注意が必要となる。
When one processor modifies a value in its cache, other processors cannot use the old value anymore. That memory location will be invalidated in all of the caches. Furthermore, since caches operate on the granularity of cache lines and not individual bytes, the entire cache line will be invalidated in all caches!
その他の参照リンク
岸辺露伴は動かないを読みました。

先週に会社研究の件で訪日して書店で買って、戻ってからゆったりと読み切りました。(SPIテストの本買わずに帰ったのが本当に腹立ますけど)
韓国でも「ジョジョの奇妙な冒険」シリーズは結構有名であって、正式に翻訳されてて販売してます。ですがまだ「岸辺露伴は動かない」本は1巻しか販売してないですし、日本では続編が7月に発売したそうですのでこのついでに日本で全部買っておこうとして買ったんです。
で、面白かった?
面白かったです!本当に。
スタンドが出て敵と戦闘をしたりする普通の展開じゃなくてただの岸辺露伴というキャラクターを借りて様々なエピソードを語りだすだけでしたけど、その奇妙な雰囲気は相変わらず。むしろこの短編に奇妙さがもっと染み込んでいるかもしれませんね。
そしてスピンオフだとしても本編のストーリーとは全然関係がなく、絵柄が消化できる人なら誰でも楽しんで見れる漫画だと思います。3巻が楽しみですねー。