Gallery of Processor Cache Effectsを読んでメモ
参照リンク
Gallery of Processor Cache Effects
Example 1 : Memory accesses and performance
int[] arr = new int[64 * 1024 * 1024]; // Loop 1 for (int i = 0; i < arr.Length; ++i) { arr[i] *= 3; } // Loop 2 for (int i = 0; i < arr.Length; i += 16) { arr[i] *= 3; }
- 理論上、Loop1がLoop2より凡そ16倍くらい遅れるそうけど、実際にはそうでもないことがわかる。記事ではほぼ同じ処理時間を持って
80msと78msが測定するそうだ。 - なぜなら、配列を構成するメモリーが一列で整列されているとしたら、Loop1とLoop2を処理するにメモリの特定地点に接近するために同じ時間を費やさなければならない。ここでキャッシュが関与してしまう。
Example 2 : Impact of cache lines
for (int i = 0; i < arr.Length; i += K) { arr[i] *= 3; }
でKの増加による処理時間を測定したらこうなる。
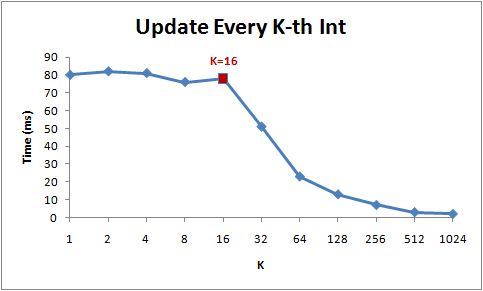
- 1から16までは理論としては処理時間が減少の傾向を見せるべきだが、実際にはそうでもないことがわかる。そして16からは急に処理時間が減少していることが分かる。
- 何故なら、現在のCPUはメモリの領域に接近する時にバイト単位で接近せずに64Bytes単位として扱う。この各64BytesをCache Lineという。メモリの特定領域を読むときに、そのCache Lineが取り出されてCacheにフェッチされる。よって、同じCache Lineでの接近は処理速度を速くする。(メモリーの地域性)
- よって16個を超えてステップをするようにすると、キャッシュミスになり、また別のCache LineをCacheに乗せなければならない。とあるデータ構造でのノードがCache Lineを犯して頻繁に接近を求めていたら犯しているCache Lineの分に処理時間が遅くなる可能性がある。
Example 3 : L1 and L2 Cache sizes
現代のCPUではキャッシュのレベルがあり、L1,L2そしてL3レベルのキャッシュメモリーが提供されている。筆者はL1メモリーの容量は32KBで、そしてL2メモリーの容量は4MBだらしい。
筆者はCache LineやCache Missを研究するために大きい配列にCache Lineごとを接近するようとしたコードを作成した。そして配列のサイズによる各要素の処理速度を測定する。
int steps = K * (1024 * 1024); for (int i = 0; i < steps; ++i) { // Start time arr[(i * 16) & arr.Length]++; // End time }
結果として得られた処理時間のグラフは以下のようになっている。
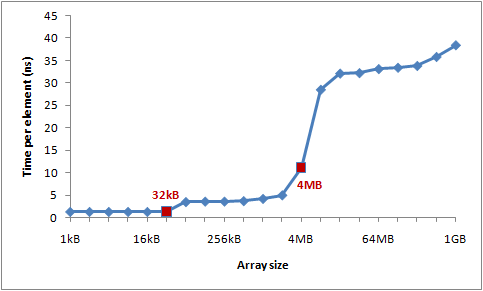
- L1キャッシュミス、そしてL2キャッシュミスによる処理時間の増加のようだ。
Example 4 : Instruction-level parallelism
int steps = 256 * 1024 * 1024; int[] a = new int[2]; // Loop 1 for (int i=0; i<steps; i++) { a[0]++; a[0]++; } // Loop 2 for (int i=0; i<steps; i++) { a[0]++; a[1]++; }
上記のLoopでは最適化によってLoop1がLoop2より遅くなる可能性がある。g++かclangのようなC++コンパイラとはまた違うが、C#のCLR JITコンパイラーは{ a[0]++; a[0]++; }を{ a[0] += 2; }で返さない。すなわち、このような従属性が生じてしまう。

- Loop2の場合には、命令語レベルの並列性が発生するため同時にL1キャッシュの変数
a[0]とa[1]に接近することができる。 - Loop1の場合、CLR JITによる最適化が行っていない場合並列処理が発生しないため速度が落ちる可能性がある。
- だとしても、コンパイラによって最適化が出来るかないかが分かれるので状況によって違われるかもしれない。
Example 5 : Cache associativity
メモリーの領域をどうやってキャッシュに乗せるかについてはいくつかの方法がある。メモリー空間をマッピングするには3つの方式がある。
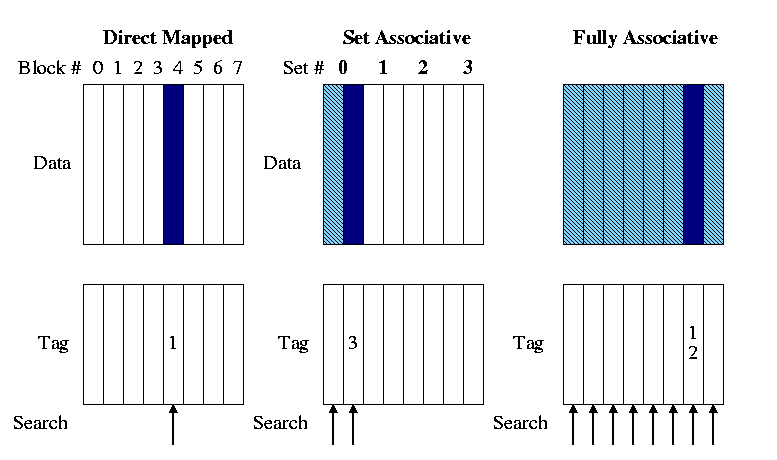

- Directed Mapped Cache
MLBからのいくつかのビットを使用し、そのままCacheにインデックスやあとでキャッシュを参照する時に使われるTagに適用する上位ビットをマッピングするものを指す。もし4GBの物理的メモリがあるとしてキャッシュは64Bytes分の番地が乗せるようになっていたら、その64Bytes分のCacheに載せられる数は64MB個になる。そのため、キャッシュミスが起こりやすい。
N-wayから見ればDirected Mapped Cacheは1-Way set associative Cacheかもしれない。indextagvalid bitoffset

- N-way set associative Cache
メモリの領域がK個で別れていて、そしてキャッシュにメモリブロックごとに一個ずつでのべ最適K個の
Setが指定され、そしてSetには指定されたメモリブロックのIndexやTagを持つようにしたN個のライン(Line)があるもの。Directed Mappedとの違いは、キャッシュを検証する時にN個を同時に検証することと構造がより優れるためキャッシュヒット率がDirected Mapped Cacheより高いのが長所である。 そしてもっと発展した構造であるFully Associative Cacheが実装しやすいという点もある。

- Fully associative Cache
Indexがなく、全てのCache lineを一つのN-way setと見なす。そのためキャッシュを検証する時にはすべてのキャッシュラインを同時に検証する。しかしIndexがなくTagOffsetだけで構成するため、検証が難しい。もしキャッシュミスが起こった場合にはN-wayのようにLRUFIFORoundrobinなどのアルゴリズムを使って代替を行う。
筆者のL2キャッシュは4MBでそして16-way set associative cacheで駆動しているそうだ。そして64Bytesもメモリブロックが一個のセットとしてあるとして32ビットの環境なら一個のセットにつき16スロットが配分される。
またキャッシュにはスロットの数の制限もあり、今の場合には65536個が限界となっている。だとしたら今使えるセットの個数は4096個となる。セット付きに一つのインデックスが割当するので2^12 = 4096個として12ビットがインデックスとして活用される。そうなればメモリの領域で一つのセットに干渉するメモリ空間の隔ては4096 * 64 = 262,144Bytesになる。こうして普通のDirected Mapped Cacheより効率を上げられる。
public static long UpdateEveryKthByte(byte[] arr, int K) { const int rep = 1024*1024; // Number of iterations int p = 0; for (int i = 0; i < rep; i++) { arr[p]++; p += K; if (p >= arr.Length) p = 0; } }
上記のコードをテストとして使用して、キャッシュによる処理速度を検証する。Kは配列の各番地を渡るステップとして扱われる。

上の画像はステップと配列のサイズによって違われる処理時間をグラフとして表示したものである。青ければ青いほど処理時間が遅い。
- ステップが
64になるまでは大差が出ない。キャッシュのほぼ全てのセットを周期的に接近するし、そして集中的に特定のセットのキャッシュ検証が行われていないからかもしれない。 128256512から見える青い先はキャッシュメモリの同じセットに集中的に接近し、アドレスを検証したり接近するため処理時間が遅くなることを示す。- 配列の大きさが
4MB以下では速度が速くなることは、今筆者のL2キャッシュメモリが4MBの容量と16-wayで配列の全ての変数の値に対するアドレスを全部入れることが出来るからだ。今各セットにつき262,144Bytesを間隔としているなら262,144 * 16 = 4MBになる。
Example 6 : False cache line sharing
- 普通L1キャッシュは各プロセッサーについており、L2からのキャッシュメモリは複数のプロセッサが共有する。
- マルチコアプロセッサの環境では接近する変数のメモリに対するキャッシュラインが同じであれば、むしろ速度が落ちることがある。何故なら、各プロセッサーが変数に接近して値を更新するたびに他のプロセッサーが持っているキャッシュラインを無効化してしまう。こういうことは普通各プロセッサーが共有するL2メモリで起こりやすく、注意が必要となる。
When one processor modifies a value in its cache, other processors cannot use the old value anymore. That memory location will be invalidated in all of the caches. Furthermore, since caches operate on the granularity of cache lines and not individual bytes, the entire cache line will be invalidated in all caches!