Segment Treeを使用して部分和を計算する。
Segment Tree とは
Segment Treeはバイナリツリー(二分木)を使用して区間やあるリストの範囲を貯蔵するに使われるデータ構造である。Segment Treeは実装するリストの長さに対していつも平衡二分探索木である。なので探索に最悪O(lgN)がかかる。Segment Treeを使用すれば、クエリーを用いてある特定の区間の部分和をO(lgN + K)で求めることができる。Kとは求められる区間の部分区間の個数を指す。
| Segment Tree | 数式 |
|---|---|
| 要素の数 | |
| ツリーの深さ | |
| ツリーのメモリ | |
| ツリーの空間複雑度 | |
| 生成の時間複雑度 | |
| 部分和の時間複雑度 | |
になる。
Segment Treeはリストが長く、そしてリストの要素の数が固定されて頻繁にリストの要素が値が切り替わるときに有用になる。
コード
Segment Tree 実装

- Segment Treeの実装に注意する点は、インプットとして入れたリストの要素の位置はツリーの葉部分であることだ。
- そして葉が生成される位置は、ツリーの左から寄せて生成するのではなく再帰に沿って仮想の完全二分木の葉の部分かそれとも葉の親部分を葉として扱ってそれらからの一つに葉が生成される。なので
Segment Treeを生成する時には、空白の葉ノードが必要となる。
using TSegmentTree = std::vector<int>; using TValueList = std::vector<int>; TSegmentTree::value_type MakeSegmentTree( const TValueList& valueList, TSegmentTree& segmentTree, const unsigned nodeIndex, const unsigned valueStart, const unsigned valueEnd) { if (valueStart == valueEnd) { segmentTree[nodeIndex] = valueList[valueStart]; } else { const auto sep = (valueStart + valueEnd) / 2; segmentTree[nodeIndex] = MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 1, valueStart, sep) + MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 2, sep + 1, valueEnd); } return segmentTree[nodeIndex]; }
部分和の関数実装
- 部分和を実装する関数を作る時には、区間の範囲だけでなくツリーの範囲まで入れないとならない。何故なら再帰によって既に計算された部分区間の和が入った親ノードを選ぶかないかを決定しなければならない為だ。
- もし再帰で今求められる区間が部分ツリーが持っている葉の要素のインデックスの範囲の相応していたら、今指している親ノードの部分和の値を返す。
- それとも区間が外されている場合にはまた掘り下げて葉まで下る。
- 区間が範囲の完全に外していたらその部分ツリーでは値を求む必要がないので
を返す。
[[nodiscard]]
TSegmentTree::value_type GetPartialSum(
const TSegmentTree& segmentTree,
const unsigned targetStart, const unsigned targetEnd,
const unsigned treeStart, const unsigned treeEnd,
const unsigned id = 0) {
// Special case
if (targetEnd < treeStart || treeEnd < targetStart) { return 0; }
if (targetStart <= treeStart && treeEnd <= targetEnd) { return segmentTree[id]; }
// General case
const auto sep = (treeStart + treeEnd) / 2;
return GetPartialSum(segmentTree, targetStart, targetEnd, treeStart, sep, 2 * id + 1)
+ GetPartialSum(segmentTree, targetStart, targetEnd, sep + 1, treeEnd, 2 * id + 2);
}
値切り替えの関数実装
- 値を切り替える場合にも再帰を積極的に使う。
- ただし、切り替えを
で終わらせてまた
Constant Factorを減らすためには今切り替えをする値に対し、既存の値との差を求めてその値が入る予定の葉までの親ノードに入っている部分和の値を新たに演算しなければいけない。
void UpdateValue( TSegmentTree& segmentTree, const unsigned valueId, const int difference, const unsigned treeStart, const unsigned treeEnd, const unsigned treeId = 0) { // Special case if (valueId < treeStart || valueId > treeEnd) { return; } // General case segmentTree[treeId] += difference; if (treeStart == treeEnd) { return; } const auto sep = (treeStart + treeEnd) / 2; UpdateValue(segmentTree, valueId, difference, treeStart, sep, 2 * treeId + 1); UpdateValue(segmentTree, valueId, difference, sep + 1, treeEnd, 2 * treeId + 2); }
結果
// 最初のインプットリスト 5 6 8 3 1 3 1 4 2 4 // Segment Treeの各ノードの値 37 23 14 19 4 8 6 11 8 3 1 4 4 2 4 5 6 0 0 0 0 0 0 3 1 0 0 0 0 0 0 // 部分和の結果リスト Start : 0 ~ End : 0 = Sum : 5 Start : 0 ~ End : 1 = Sum : 11 ... Start : 0 ~ End : 7 = Sum : 31 Start : 0 ~ End : 8 = Sum : 33 Start : 0 ~ End : 9 = Sum : 37 Start : 1 ~ End : 9 = Sum : 32 Start : 2 ~ End : 9 = Sum : 26 ... Start : 8 ~ End : 9 = Sum : 6 Start : 9 ~ End : 9 = Sum : 4 // 新たな値リスト 17 -34 -59 71 86 25 83 33 53 -89 // 更新したSegment Treeの各ノードの値 186 81 105 -76 157 141 -36 -17 -59 71 86 108 33 53 -89 17 -34 0 0 0 0 0 0 25 83 0 0 0 0 0 0
コード全文
#include <cstdio> #include <vector> #include <algorithm> #include <utility> #include "../../Common/CheckTime.hpp" using TSegmentTree = std::vector<int>; using TValueList = std::vector<int>; TSegmentTree::value_type MakeSegmentTree( const TValueList& valueList, TSegmentTree& segmentTree, const unsigned nodeIndex, const unsigned valueStart, const unsigned valueEnd) { if (valueStart == valueEnd) { segmentTree[nodeIndex] = valueList[valueStart]; return segmentTree[nodeIndex]; } else { const auto sep = (valueStart + valueEnd) / 2; segmentTree[nodeIndex] = MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 1, valueStart, sep) + MakeSegmentTree(valueList, segmentTree, 2 * nodeIndex + 2, sep + 1, valueEnd); return segmentTree[nodeIndex]; } } [[nodiscard]] TSegmentTree::value_type GetPartialSum( const TSegmentTree& segmentTree, const unsigned targetStart, const unsigned targetEnd, const unsigned treeStart, const unsigned treeEnd, const unsigned id = 0) { // Special case if (targetEnd < treeStart || treeEnd < targetStart) { return 0; } if (targetStart <= treeStart && treeEnd <= targetEnd) { return segmentTree[id]; } // General case const auto sep = (treeStart + treeEnd) / 2; return GetPartialSum(segmentTree, targetStart, targetEnd, treeStart, sep, 2 * id + 1) + GetPartialSum(segmentTree, targetStart, targetEnd, sep + 1, treeEnd, 2 * id + 2); } void UpdateValue( TSegmentTree& segmentTree, const unsigned valueId, const int difference, const unsigned treeStart, const unsigned treeEnd, const unsigned treeId = 0) { // Special case if (valueId < treeStart || valueId > treeEnd) { return; } // General case segmentTree[treeId] += difference; if (treeStart == treeEnd) { return; } const auto sep = (treeStart + treeEnd) / 2; UpdateValue(segmentTree, valueId, difference, treeStart, sep, 2 * treeId + 1); UpdateValue(segmentTree, valueId, difference, sep + 1, treeEnd, 2 * treeId + 2); } int main() { // Make valueList; std::vector<int> valueList = {}; for (int i = 0; i < 10; ++i) { valueList.emplace_back(neu::test::GetRandomValue<int>(1, 10)); } // Print valueList; for (const auto& value : valueList) { std::printf("%d ", value); } std::puts(""); // Make segment Tree; const auto height = static_cast<unsigned>(std::ceil(std::log2(valueList.size()))) + 1; std::vector<int> segmentTree((1 << height) - 1, 0); MakeSegmentTree(valueList, segmentTree, 0, 0, valueList.size() - 1); // Pritn segment Tree. for (const auto& value : segmentTree) { std::printf("%d ", value); } std::puts(""); // Get Sum from segmentTree rapidly O(lgN) unsigned start = 0; unsigned end = 0; while (end <= valueList.size() - 1) { std::printf("Start : %u ~ End : %u = Sum : %d\n", start, end, GetPartialSum(segmentTree, start, end, 0, valueList.size() - 1) ); ++end; } end--; while (start <= end) { std::printf("Start : %u ~ End : %u = Sum : %d\n", start, end, GetPartialSum(segmentTree, start, end, 0, valueList.size() - 1) ); ++start; } // Update value and get overall sum. std::vector<int> diff(valueList.size()); for (auto i = 0u; i < valueList.size(); ++i) { const auto newValue = (neu::test::GetRandomValue<int>(-100, 100)); diff[i] = newValue - valueList[i]; valueList[i] = newValue; } // Print valueList; for (const auto& value : valueList) { std::printf("%d ", value); } std::puts(""); for (auto i = 0u; i < valueList.size(); ++i) { UpdateValue(segmentTree, i, diff[i], 0, valueList.size() - 1); } // Print segment Tree. for (const auto& value : segmentTree) { std::printf("%d ", value); } std::puts(""); };
参照リンク
Segment tree - Wikipedia 세그먼트 트리(Segment Tree) 요약 정리 (C++) – Jang
Gallery of Processor Cache Effectsを読んでメモ
参照リンク
Gallery of Processor Cache Effects
Example 1 : Memory accesses and performance
int[] arr = new int[64 * 1024 * 1024]; // Loop 1 for (int i = 0; i < arr.Length; ++i) { arr[i] *= 3; } // Loop 2 for (int i = 0; i < arr.Length; i += 16) { arr[i] *= 3; }
- 理論上、Loop1がLoop2より凡そ16倍くらい遅れるそうけど、実際にはそうでもないことがわかる。記事ではほぼ同じ処理時間を持って
80msと78msが測定するそうだ。 - なぜなら、配列を構成するメモリーが一列で整列されているとしたら、Loop1とLoop2を処理するにメモリの特定地点に接近するために同じ時間を費やさなければならない。ここでキャッシュが関与してしまう。
Example 2 : Impact of cache lines
for (int i = 0; i < arr.Length; i += K) { arr[i] *= 3; }
でKの増加による処理時間を測定したらこうなる。
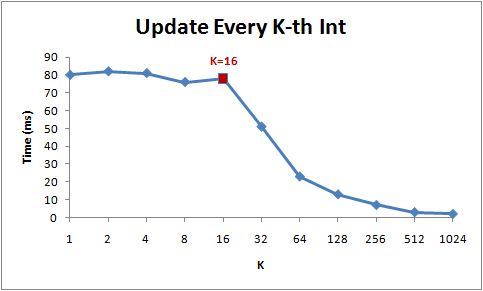
- 1から16までは理論としては処理時間が減少の傾向を見せるべきだが、実際にはそうでもないことがわかる。そして16からは急に処理時間が減少していることが分かる。
- 何故なら、現在のCPUはメモリの領域に接近する時にバイト単位で接近せずに64Bytes単位として扱う。この各64BytesをCache Lineという。メモリの特定領域を読むときに、そのCache Lineが取り出されてCacheにフェッチされる。よって、同じCache Lineでの接近は処理速度を速くする。(メモリーの地域性)
- よって16個を超えてステップをするようにすると、キャッシュミスになり、また別のCache LineをCacheに乗せなければならない。とあるデータ構造でのノードがCache Lineを犯して頻繁に接近を求めていたら犯しているCache Lineの分に処理時間が遅くなる可能性がある。
Example 3 : L1 and L2 Cache sizes
現代のCPUではキャッシュのレベルがあり、L1,L2そしてL3レベルのキャッシュメモリーが提供されている。筆者はL1メモリーの容量は32KBで、そしてL2メモリーの容量は4MBだらしい。
筆者はCache LineやCache Missを研究するために大きい配列にCache Lineごとを接近するようとしたコードを作成した。そして配列のサイズによる各要素の処理速度を測定する。
int steps = K * (1024 * 1024); for (int i = 0; i < steps; ++i) { // Start time arr[(i * 16) & arr.Length]++; // End time }
結果として得られた処理時間のグラフは以下のようになっている。
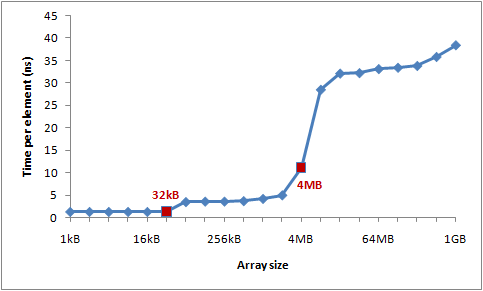
- L1キャッシュミス、そしてL2キャッシュミスによる処理時間の増加のようだ。
Example 4 : Instruction-level parallelism
int steps = 256 * 1024 * 1024; int[] a = new int[2]; // Loop 1 for (int i=0; i<steps; i++) { a[0]++; a[0]++; } // Loop 2 for (int i=0; i<steps; i++) { a[0]++; a[1]++; }
上記のLoopでは最適化によってLoop1がLoop2より遅くなる可能性がある。g++かclangのようなC++コンパイラとはまた違うが、C#のCLR JITコンパイラーは{ a[0]++; a[0]++; }を{ a[0] += 2; }で返さない。すなわち、このような従属性が生じてしまう。

- Loop2の場合には、命令語レベルの並列性が発生するため同時にL1キャッシュの変数
a[0]とa[1]に接近することができる。 - Loop1の場合、CLR JITによる最適化が行っていない場合並列処理が発生しないため速度が落ちる可能性がある。
- だとしても、コンパイラによって最適化が出来るかないかが分かれるので状況によって違われるかもしれない。
Example 5 : Cache associativity
メモリーの領域をどうやってキャッシュに乗せるかについてはいくつかの方法がある。メモリー空間をマッピングするには3つの方式がある。
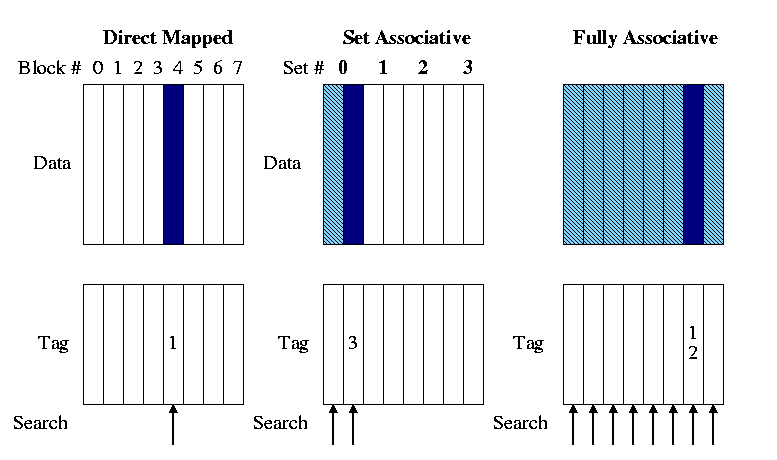

- Directed Mapped Cache
MLBからのいくつかのビットを使用し、そのままCacheにインデックスやあとでキャッシュを参照する時に使われるTagに適用する上位ビットをマッピングするものを指す。もし4GBの物理的メモリがあるとしてキャッシュは64Bytes分の番地が乗せるようになっていたら、その64Bytes分のCacheに載せられる数は64MB個になる。そのため、キャッシュミスが起こりやすい。
N-wayから見ればDirected Mapped Cacheは1-Way set associative Cacheかもしれない。indextagvalid bitoffset

- N-way set associative Cache
メモリの領域がK個で別れていて、そしてキャッシュにメモリブロックごとに一個ずつでのべ最適K個の
Setが指定され、そしてSetには指定されたメモリブロックのIndexやTagを持つようにしたN個のライン(Line)があるもの。Directed Mappedとの違いは、キャッシュを検証する時にN個を同時に検証することと構造がより優れるためキャッシュヒット率がDirected Mapped Cacheより高いのが長所である。 そしてもっと発展した構造であるFully Associative Cacheが実装しやすいという点もある。

- Fully associative Cache
Indexがなく、全てのCache lineを一つのN-way setと見なす。そのためキャッシュを検証する時にはすべてのキャッシュラインを同時に検証する。しかしIndexがなくTagOffsetだけで構成するため、検証が難しい。もしキャッシュミスが起こった場合にはN-wayのようにLRUFIFORoundrobinなどのアルゴリズムを使って代替を行う。
筆者のL2キャッシュは4MBでそして16-way set associative cacheで駆動しているそうだ。そして64Bytesもメモリブロックが一個のセットとしてあるとして32ビットの環境なら一個のセットにつき16スロットが配分される。
またキャッシュにはスロットの数の制限もあり、今の場合には65536個が限界となっている。だとしたら今使えるセットの個数は4096個となる。セット付きに一つのインデックスが割当するので2^12 = 4096個として12ビットがインデックスとして活用される。そうなればメモリの領域で一つのセットに干渉するメモリ空間の隔ては4096 * 64 = 262,144Bytesになる。こうして普通のDirected Mapped Cacheより効率を上げられる。
public static long UpdateEveryKthByte(byte[] arr, int K) { const int rep = 1024*1024; // Number of iterations int p = 0; for (int i = 0; i < rep; i++) { arr[p]++; p += K; if (p >= arr.Length) p = 0; } }
上記のコードをテストとして使用して、キャッシュによる処理速度を検証する。Kは配列の各番地を渡るステップとして扱われる。

上の画像はステップと配列のサイズによって違われる処理時間をグラフとして表示したものである。青ければ青いほど処理時間が遅い。
- ステップが
64になるまでは大差が出ない。キャッシュのほぼ全てのセットを周期的に接近するし、そして集中的に特定のセットのキャッシュ検証が行われていないからかもしれない。 128256512から見える青い先はキャッシュメモリの同じセットに集中的に接近し、アドレスを検証したり接近するため処理時間が遅くなることを示す。- 配列の大きさが
4MB以下では速度が速くなることは、今筆者のL2キャッシュメモリが4MBの容量と16-wayで配列の全ての変数の値に対するアドレスを全部入れることが出来るからだ。今各セットにつき262,144Bytesを間隔としているなら262,144 * 16 = 4MBになる。
Example 6 : False cache line sharing
- 普通L1キャッシュは各プロセッサーについており、L2からのキャッシュメモリは複数のプロセッサが共有する。
- マルチコアプロセッサの環境では接近する変数のメモリに対するキャッシュラインが同じであれば、むしろ速度が落ちることがある。何故なら、各プロセッサーが変数に接近して値を更新するたびに他のプロセッサーが持っているキャッシュラインを無効化してしまう。こういうことは普通各プロセッサーが共有するL2メモリで起こりやすく、注意が必要となる。
When one processor modifies a value in its cache, other processors cannot use the old value anymore. That memory location will be invalidated in all of the caches. Furthermore, since caches operate on the granularity of cache lines and not individual bytes, the entire cache line will be invalidated in all caches!
その他の参照リンク
岸辺露伴は動かないを読みました。

先週に会社研究の件で訪日して書店で買って、戻ってからゆったりと読み切りました。(SPIテストの本買わずに帰ったのが本当に腹立ますけど)
韓国でも「ジョジョの奇妙な冒険」シリーズは結構有名であって、正式に翻訳されてて販売してます。ですがまだ「岸辺露伴は動かない」本は1巻しか販売してないですし、日本では続編が7月に発売したそうですのでこのついでに日本で全部買っておこうとして買ったんです。
で、面白かった?
面白かったです!本当に。
スタンドが出て敵と戦闘をしたりする普通の展開じゃなくてただの岸辺露伴というキャラクターを借りて様々なエピソードを語りだすだけでしたけど、その奇妙な雰囲気は相変わらず。むしろこの短編に奇妙さがもっと染み込んでいるかもしれませんね。
そしてスピンオフだとしても本編のストーリーとは全然関係がなく、絵柄が消化できる人なら誰でも楽しんで見れる漫画だと思います。3巻が楽しみですねー。
Kahan summation algorithmを試してみました。
発端
0.01f を 10000 回足すと 100.003f になる話に関連して、カハンの加算アルゴリズムを使うと、浮動小数点数の合計を求めるときの誤差を減らせることも知っておきたい https://t.co/Ctrz6V3QQ6 pic.twitter.com/FPPrUG2v8W
— Ryo Suzuki (@Reputeless) 2018年11月19日
発端はこの@Reputelessさんのツイートからです。
コンピューターが発明された以後、そして2進数が発明してメモリ領域のあらゆる値を表現するにとって採用されてから浮動小数点は大きな数まで表現できるようになりました。
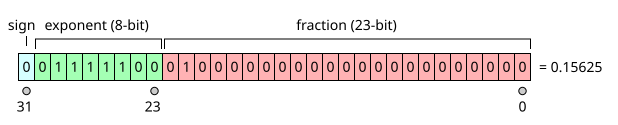
しかし浮動小数点は整数とは表現が違って浮動小数点は単なる2進数の羅列じゃなくIEEE754という表現の規定にそってメモリの領域の2進数を操ります。そしてその表現による重大な問題があります。
すべての素数を完全に表現することができないという事です。何故ならIEEE754の表現によると、0.01みたいな素数てんは2進数でぴったりと表現できることができません。0.5 0.25のように2で割れられる小数点は誤差なしに表現できますが、0.01の場合には実際には0.001000001みたいになってしまいます。
勿論浮動小数点一つ一つの誤差は大きくないですが、問題はこの浮動小数点を何千回も演算すると誤差が大きくなって、望ましい値とはだいぶ違ってしまいます。その誤差による演算が違ってしまうのを防ぐために開発されたのがPairwise summationかKahan Summation Algoritihmです。今回はPairwiseの代わりにKahanを取り上げてみたいと思います。
説明
Kahan summation algorithm - Wikipedia
Kahan summation algorithmは浮動小数点の演算の際に正確度の欠如による誤差を減らす為のアルゴリズムである。Pairwise summation algorithmとは違いリストの形で一連の浮動小数点を渡さなくても、実時間で補正を行うことができる。
浮動小数点をN個演算するときに、最悪の場合Nに比例して誤差(Error)が大きくなる傾向がある。しかし演算するときに補正を行うと最悪の場合にもエラーバウンドはNに独立となり、ただ今使っている浮動小数点の正確度だけに依存するようになる。
実装コード
void KahanProcess(std::vector<float>& input) { auto com = 0.0f; for (const auto& value : input) { const auto y = value - com; const auto t = kahanSum + y; com = (t - kahanSum) - y; (void)com; kahanSum = t; } }
このアルゴリズムで注目すべきのところはcomに補正を入れて、浮動小数点の正確度の欠如によるアンダフローを防ぐことだと思います。そして浮動小数点ごとの補正を演算するために、今までの合計を引き算してcomを求めます。
Neumaier-Summationという、Kahanからより正確に補正を行うアルゴリズムも存在します。
結果
私がテストしたコードではstd::vector<>に1,000,000個の0.01fを入れてこれらを和して10,000.0からいくらの誤差が出るかを検証します。そしてコード演算の結果、このように出ました。
PS C:\Users\jmyun\Documents\Dev\SH-Algorithm\Algorithm\KahanCompensation> .\a.exe Test "Plain-Sum" took 1415200ns. Test "Kahan-Sum" took 5268500ns. Expected : 10000.000000 Given(Plain-Sum) : 9865.223633 Given(Kahan-Sum) : 10000.000000
普通(Plain)に小数点を和したのは9865.224の10000から随分離れた数値が出たのが分かりますが、Kahanを使用すると補正により10,000.0が求められるのを確認できます。勿論補正のための追加演算が行われますので普通の和よりはだいぶ遅いです。
そのためのPairwise-Summationというまた別の和演算補正アルゴリズムがありますが、そちらは誤差がO(lgN)に比例している短所や浮動小数点をまとめたリストの形で渡さなければならない短所があります。(だとしてもPlainよりは誤差がほぼないです。)
参照
Chapter 3 Typelists メモ (1)
Typelists
- Typelistというのは支援する値に関した一連の型をリスト化して提供する道具である。3章ではこのTypelistを実装する。
- Typelistが有用に使用されるところは、Abstract Factoryか、Visitorパターンでよく使われる。
3.2 Defining Tyeplists ~ 3.6 Indexed Access
Typelistは2つのタイプを持つことができる。この2つのタイプの別称をHead、Tailと呼ぶ。そしてTypelistのTailにまた別のTypelistをつけて複数のタイプを持つように調整することもできる。- しかし、タイプが複数存在する場合には、最後の型をもう以上締めるということで
NullTypeという別のタイプを使って閉まる。これによってHalf-opened rangeが構成できる。 Typelistに複数の型を用意するには一つ一つ書く方法もあるけど、本にはMacroを使って個数ごとにマクロを使用して簡単にTypelistリストを作成できるようにした。しかし、僕はマクロを使わずにTypelistPackage::typeを実装して、可変長型引数を入れてリストを作るようにした。length変数テンプレートはTypelistリストに対していくつかの型を貯めているかを示す。NullTypeの場合には0を返す。
#include <type_traits> struct NullType final {}; template <class T, class U> struct Typelist final { using Head = T; using Tail = U; }; template <class... TArgs> struct TypelistPackage final { private: template <class... TTypeArgs> struct Constructor; template <class TType> struct Constructor<TType> final { using type = Typelist<TType, NullType>; }; template <class TType, class... TTypeArgs> struct Constructor<TType, TTypeArgs...> final { using type = Typelist<TType, typename Constructor<TTypeArgs...>::type>; }; public: using type = typename TypelistPackage::Constructor<TArgs...>::type; }; template <class TList> constexpr unsigned int length = 0; template <> constexpr unsigned int length<NullType> = 0; template <class TT, class TU> constexpr unsigned int length<Typelist<TT, TU>> = 1 + length<TU>;
using Charlist = TypelistPackage<char, signed char, unsigned char>::type; using SingedInts = TypelistPackage<signed char, short int, int, long int>::type; static_assert(length<SingedInts> == 4, "");
TypeAtはTypelistのリストからインデックス番地にある型を取り出すために作られたものである。- 本で主要に扱われているライブラリーのLokiでは、この
TypeAtのデフォルト値を返すバージョンであるTypeAtNonStrictも実装されている。 Typelistを使用し番地を探索することはリストや番地の数が多いばあい、ビルドタイムの低下を招きやすい。
template <class TList, unsigned int TIndex> struct TypeAt; template <class THead, class TTail> struct TypeAt<Typelist<THead, TTail>, 0> final { using type = THead; }; template <class THead, class TTail, unsigned int TIndex> struct TypeAt<Typelist<THead, TTail>, TIndex> final { using type = typename TypeAt<TTail, TIndex - 1>::type; }; static_assert(std::is_same_v<TypeAt<SingedInts, 1>::type, short int>, "");
3.7 Searching Typelists ~ 3.9 Erasing a Type from a Typelist
IndexOfは任意のTypelistに任意の型Tを入れると、Typelistにある型リストから当てはまる型のインデックスを返すようにする。- もし
NullTypeか型を探せなかったら,-1を返す。
template<class TList, class TTarget> struct IndexOf; template <class TTarget> struct IndexOf<NullType, TTarget> { enum { value = -1 }; }; template <class TTarget, class TTail> struct IndexOf<Typelist<TTarget, TTail>, TTarget> final { enum { value = 0 }; }; template <class THead, class TTail, class TTarget> struct IndexOf<Typelist<THead, TTail>, TTarget> final { private: enum { temp = IndexOf<TTail, TTarget>::value }; public: enum { value = temp == -1 ? -1 : temp + 1 }; };
using SignedIntegrals = SingedInts; static_assert(IndexOf<SingedIntegrals, int>::value == 2, "");
Appendを使用してTypelistを既存のTypelistに入れたり、単一タイプをTypelistに入れるようにする。再起を用いて既存のTypelistのNullType部分を入れ替えるようにした。
template <class TList, class TType> struct Append; template <> struct Append<NullType, NullType> { using type = NullType; }; template <class TTarget> struct Append<NullType, TTarget> { using type = Typelist<TTarget, NullType>; }; template <class THead, class TTail> struct Append<NullType, Typelist<THead, TTail>> { using type = Typelist<THead, TTail>; }; template <class THead, class TTail, class TTarget> struct Append<Typelist<THead, TTail>, TTarget> { using type = Typelist<THead, typename Append<TTail, TTarget>::type>; }; template <class TList, class TType> using Append_T = typename Append<TList, TType>::type;
using Charlist = TypelistPackage_T<char, signed char, unsigned char>; using OneTypeOnly = TypelistPackage_T<int>; using SingedIntegrals = TypelistPackage_T<signed char, short int, int, long int>; using SignedIntegralsAdded = Append_T<SingedIntegrals, char>; static_assert(IndexOf_V<SignedIntegralsAdded, char> == 4, ""); static_assert(IndexOf_V<SignedIntegralsAdded, int> == 2, ""); using Integrals = Append_T< SingedIntegrals, TypelistPackage_T<unsigned char, unsigned short, unsigned, unsigned long> >; static_assert(IndexOf_V<Integrals, unsigned> == 6, ""); static_assert(IndexOf_V<Integrals, int> == 2, "");
EraseはTypelistから特定のタイプを取り外す役割をする。本ではEraseと再帰を行うEraseAllが実装しているが私の場合にはbool定数を使ってEraseだけで処理を行うようにした。
template <class TList, class TType, bool TIsAll> struct Erase; template <class TType, bool TIsAll> struct Erase<NullType, TType, TIsAll> { using type = NullType; }; template <class TTail, class TType> struct Erase<Typelist<TType, TTail>, TType, false> { using type = TTail; }; template <class TTail, class TType> struct Erase<Typelist<TType, TTail>, TType, true> { using type = typename Erase<TTail, TType, true>::type; }; template <class THead, class TTail, class TType, bool TIsAll> struct Erase<Typelist<THead, TTail>, TType, TIsAll> { using type = Typelist<THead, typename Erase<TTail, TType, TIsAll>::type>; }; template <class TList, class TType, bool TIsAll = false> using Erase_T = typename Erase<TList, TType, TIsAll>::type;
using IntegralsExceptChar = Erase_T<SingedIntegrals, char>; static_assert(IndexOf_V<IntegralsExceptChar, char> == -1, ""); using CharChunk = TypelistPackage_T<char, char, int, int, char, char>; static_assert(length<Erase_T<CharChunk, char, true>> == 2, "");
3.10 Erasing Duplicates ~ 3.11 Replacing an Element in a Typelist
Typelistに存在する重複する型を一つに締め付けるために、AlignTypelistを実装する。実装するに以前に実装sしたEraseを活用する。- しかし
Eraseを活用するときに注意するところはTIsAllがfalseというところである。なぜなら、__type1を型引数として使用してEraseを行う。そして__type1は再帰的にAlignTypelistを既に行ってから結果として出すTypelist型を使用する。そのため、再帰的にEraseする必要が無くなる。
template <class TList> struct AlignTypelist; template <> struct AlignTypelist<NullType> { using type = NullType; }; template <class THead, class TTail> struct AlignTypelist<Typelist<THead, TTail>> { private: using __type1 = typename AlignTypelist<TTail>::type; using __type2 = Erase_T<__type1, THead>; public: using type = Typelist<THead, __type2>; }; template <class TList> using AlignTypelist_T = typename AlignTypelist<TList>::type;
using CharChunk = TypelistPackage_T<char, char, int, int, char, char>; using AlignedCharChunk = AlignTypelist_T<CharChunk>; static_assert(1 && length<AlignedCharChunk> == 2 && std::is_same_v<TypeAt_T<AlignedCharChunk, 0>, char> && std::is_same_v<TypeAt_T<AlignedCharChunk, 1>, int>, "MUST BE SUCCEEDED." );
Replaceは特定の型を探して別の型に入れ替えることを受け取っている。そしてEraseの再帰バージョンのようにReplaceもIsApplyAll<false>IsApplyAll<true>を使用して再帰かないかを定められる。
template <class TList, class TTarget, class TReplace, class TIsApplyAll> struct Replace; template <class TList, class TTarget, class TReplace, class TIsApplyAll> using Replace_T = typename Replace<TList, TTarget, TReplace, TIsApplyAll>::type; template <class TTarget, class TReplace, class TIsApplyAll> struct Replace<NullType, TTarget, TReplace, TIsApplyAll> { using type = NullType; }; template <class TTail, class TTarget, class TReplace> struct Replace<Typelist<TTarget, TTail>, TTarget, TReplace, IsApplyAll<false>> { using type = Typelist<TReplace, TTail>; }; template <class TTail, class TTarget, class TReplace> struct Replace<Typelist<TTarget, TTail>, TTarget, TReplace, IsApplyAll<true>> { using type = Typelist< TReplace, Replace_T<TTail, TTarget, TReplace, IsApplyAll<true>> >; }; template <class THead, class TTail, class TTarget, class TReplace, class TIsApplyAll> struct Replace<Typelist<THead, TTail>, TTarget, TReplace, TIsApplyAll> { using type = Typelist< THead, Replace_T<TTail, TTarget, TReplace, TIsApplyAll> >; };
using CharChunk = TypelistPackage_T<char, char, int, int, char, char>; static_assert( std::is_same_v< TypeAt_T< AlignTypelist_T<Replace_T<CharChunk, char, short, IsApplyAll<true>> >, 0> , short>, "MUST BE SUCCEEDED." );